AI networking refers to the convergence of artificial intelligence (AI) technologies with networking, encompassing two complementary concepts: Using AI to optimize and automate network operations (often termed “AI for networking”), and designing high-performance fabric networks to support AI workloads (termed “networking for AI”).
In practice, AI networking means smarter, self-optimizing networks on one hand, and ultra-fast, scalable ExpoTech AI Generated data centers’ fabrics on the other. This dual perspective is shaping modern network infrastructure—from autonomous network management systems to specialized cluster interconnects that link thousands of AI processors in parallel.
A specialized, high-performance infrastructure designed to meet the extreme demands of artificial intelligence, machine learning (ML), and large language model (LLM) workloads. Unlike traditional data center networks, which handle bursty, north-south traffic (client-to-server), ExpoTech’s Al Generated Data Centers’ AI networks are optimized for “east-west” traffic (server-to-server) to support massive parallel processing and distributed training.
Key Differences: Traditional vs. AI-Driven Networking
|
Feature
|
Traditional Data Center
|
AI-Driven Data Center
|
|---|---|---|
|
Traffic Pattern
|
North-South (User to Server)
|
East-West (Server to Server)
|
|
Bandwidth
|
Medium (10/100 GbE)
|
Extremely High (400/800 GbE+)
|
|
Latency
|
Milliseconds
|
Microseconds (Low Latency)
|
|
Packet Loss
|
Tolerant (TCP Retransmission)
|
Lossless Required (RoCEv2/PFC)
|
|
Management
|
Manual/CLI-Based
|
Intent-Based Automation/AI
|
AI for Networking: ExpoTech’s Al Generated Data Centers’ AI-Driven Network Operations
AI for networking involves applying AI and machine learning to monitor, manage, and secure networks automatically. Instead of static scripts or manual tweaks, AI-driven networks can analyze vast telemetry data, learn normal patterns, and respond to issues in real time.
ExpoTech’s Al Generated Data Centers’ Key capabilities include:
- Automated Network Management: AI systems ingest diverse network telemetry (device logs, flow records, routing updates, etc.) to detect anomalies and performance issues faster than human network operators. For example, machine learning models can spot unusual traffic spikes or latency jumps and pinpoint root causes across complex topologies.
This proactive analysis helps identify outages, misconfigurations, or security threats before they impact users. By converting raw data into insights, AI effectively becomes an expert “network analyst” on the team.
- Self-Optimization: AI-enabled networks continuously learn and adjust. They can predict congestion or failures and automatically reconfigure routing and traffic flows to optimize performance.
For example, if an AI model foresees a link reaching capacity, the system might reroute some traffic or balance loads elsewhere, without waiting for human intervention. Such self-optimizing behaviour keeps networks running smoothly even as conditions change.
- Closed-Loop Automation: AI for networking enables closed-loop workflows where detection and remediation are tightly integrated. When an anomaly is detected, the system doesn’t just alert a human—it can trigger automated actions (with safety checks). This could mean automatically resetting a flapping interface, black holing DDoS traffic, or adjusting QoS policies in response to detected congestion.
Over time, the ExpoTech’s Al Generated Data Centers’ Networking AI will learn which actions fix which issues, continually improving its recommendations. Networks thus become self-healing and require fewer manual fixes.
- Enhanced Security: AI and ML greatly bolster network security by analyzing traffic for threats in ways traditional network monitoring tools can’t. ExpoTech’s Al Generated Data Centers’ Networking AI-driven security system can sift through millions of log entries and flow records to find the needle-in-a-haystack signs of malware or intrusions—often faster and with fewer false positives than static rules. It learns baseline behaviours and flags anomalies (e.g., a sudden data exfiltration or a DDoS attack pattern) instantly. AI can also automatically enforce security policies. For example, blocking suspicious IPs or quarantining compromised devices in response to an alert.
This rapid, adaptive defence is crucial as networks face increasingly sophisticated cyber attacks. By reducing alert fatigue and accelerating incident response, AI-driven security keeps networks safer. These capabilities make AI-driven networks far more efficient and reliable. An AI-powered network management platform effectively acts as a virtual engineer that never sleeps. It correlates data, predicts problems, and takes action in seconds, enabling a shift from reactive troubleshooting to proactive assurance.
Flow Control and Congestion Avoidance
-
Aside from fabric capacity, there are additional design considerations that contribute to the overall dependability and efficiency of the fabric. This encompasses appropriately sized fabric interconnects with the correct number of links, enabling the identification and rectification of flow imbalances to prevent congestion and packet loss. The combination of ExpoTech’s Explicit Congestion Notification (ECN), data center quantized congestion notification (DCQCN), and priority-based flow control effectively resolves flow imbalances, ensuring the transmission remains free of losses.
-
To address congestion, dynamic and adaptive load balancing techniques are implemented at the switch level. Dynamic load balancing redistributes flows within the switch locally to achieve a balanced distribution. Adaptive load balancing continuously monitors flow forwarding and next hop tables, identifying imbalances and redirecting traffic away from congested paths.
-
In cases where congestion cannot be entirely avoided, ECN provides early notification to applications. During these instances, leafs and spines update packets to support ECN, informing senders about congestion and prompting them to slow down transmission to prevent packet drops during transit. If endpoints fail to react promptly, priority-based flow control (PFC) enables Ethernet receivers to communicate buffer availability feedback to senders. During periods of congestion, leafs and spines can pause or regulate traffic on specific links, effectively reducing congestion and preventing packet drops. This ensures lossless transmission for specific traffic classes.
ExpoTech’s Al Generated Data Centers’ Networking Scale and Performance
-
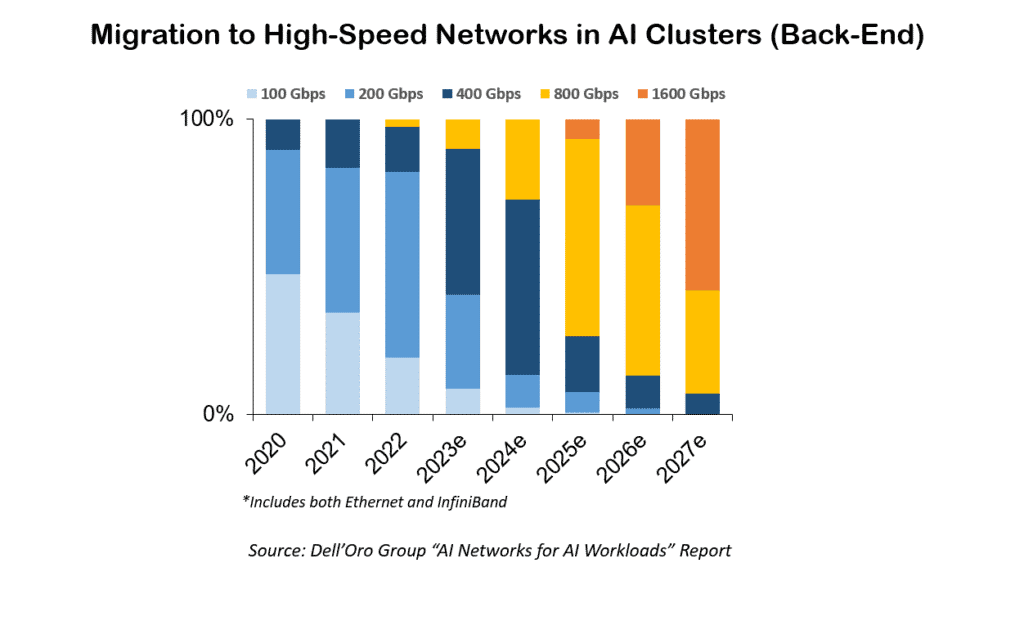
Ethernet has emerged as the favoured open-standard resolution for addressing the rigorous demands of high-performance computing and AI applications. It has undergone continuous evolution, encompassing advancements like the transition to 800 GbE and data center bridging (DCB), in order to offer enhanced speed, reliability, and scalability. Consequently, Ethernet stands as the optimal selection for managing the substantial data throughput and low-latency requirements essential to mission-critical AI applications.
-
To address congestion, dynamic and adaptive load balancing techniques are implemented at the switch level. Dynamic load balancing redistributes flows within the switch locally to achieve a balanced distribution. Adaptive load balancing continuously monitors flow forwarding and next hop tables, identifying imbalances and redirecting traffic away from congested paths.
-
In cases where congestion cannot be entirely avoided, ECN provides early notification to applications. During these instances, leafs and spines update packets to support ECN, informing senders about congestion and prompting them to slow down transmission to prevent packet drops during transit. If endpoints fail to react promptly, priority-based flow control (PFC) enables Ethernet receivers to communicate buffer availability feedback to senders. During periods of congestion, leafs and spines can pause or regulate traffic on specific links, effectively reducing congestion and preventing packet drops. This ensures lossless transmission for specific traffic classes.
Technologies Supporting ExpoTech’s Al Generated Data Centers’ AI Networking
- Ethernet: Becoming the dominant open-standard, cost-effective, and scalable choice for AI fabrics, replacing proprietary solutions through advancements by the Ultra Ethernet Consortium (UEC).
- InfiniBand: A high-speed, low-latency technology often used for its superior performance in AI supercomputing environments.
- RDMA (Remote Direct Memory Access): Allows direct data transfer between the memory of two computers without involving the CPU, reducing latency and boosting throughput for GPU synchronization.
- Adaptive Routing: Switches dynamically select paths based on congestion, directing traffic away from overloaded links to maximize fabric utilization.
What is ExpoTech’s Al Generated Data Centers’ AI networking solution?
An interconnect solution for HPC/AI is different from a network built to serve connectivity to residential households or a mobile network as well as different than a network built to serve an array of servers purposed to answers queries from multiple users as a typical data center structure would be used for. The infrastructure must insure, via predictable and lossless communication, optimal GPU performance (minimized idle cycles awaiting network resources) and maximized JCT performance. This infrastructure also needs to be inter operable and based on an open architecture to avoid vendor lock (for networking or GPUs).
Architectural flexibility
- Multiple and diverse applications
- Support of growth
- Web connectivity (unlike isolated HPC)
High performance at scale
- Support of growth
- Huge-scale GPU deployment larger than chassis limit
- Fastest JCT via (Resilience, high availability, minimal blast radius, etc., Predictable, lossless, low-latency and low-jitter connectivity – reducing GPU idle cycles)
Trusted ecosystem
- Standard interfaces allowing multi-vendor mix-and-match – avoiding HW/ASIC vendor lock
- Field-proven interconnect solutions – reducing risk
ExpoTech’s Al Generated Data Centers’ solutions for AI networking
There are a number of notable industry solutions for AI back-end networking.
Non-Ethernet (e.g., Nvidia’s InfiniBand)

Ethernet – Clos architecture

Ethernet – Clos architecture with enhanced telemetry

Ethernet – single chassis

AI Data Gravity & Edge Considerations
AI’s thirst for data also influences where computing happens. There is a concept of data gravity — large datasets tend to attract applications to where the data resides. In AI training, the datasets (images, text corpora, etc.) are often massive (petabyte-scale) and stored in centralized cloud storage or big data hubs. It’s often more efficient to bring the computing to a central data repository than to move the data around. For this reason, AI training workloads gravitate to centralized hyperscale data centers (e.g. those run by cloud giants or large research clusters). These facilities have the petabit networking inside the data center to shuffle data, and vast storage nearby, which is critical because training is not very tolerant of wide-area network latency or bandwidth constraints. Additionally, model training doesn’t require real-time interaction with end-users, so it can be done in remote regions as long as the data is accessible. Hyperscale cloud data centers (which often exceed 50–100 MW power each) are ideal for training: they offer cost-efficient power/cooling at scale and can host thousands of GPUs in one place. In fact, model training is not very latency-sensitive to user locations, which gives flexibility to run it in a location with cheap electricity and strong infrastructure — even if it’s far from where the data was generated, the data can be transferred or aggregated there for training.
On the other hand, AI inference (deploying trained models to serve predictions) often is latency-sensitive and sometimes bandwidth-sensitive in different ways. Inference workloads are what end-users or devices interact with—for example, an autonomous vehicle’s vision system, a smart city camera analytics, or a voice assistant responding to a query. These inference tasks frequently need real-time or near-real-time responses. If every image or sensor reading had to be sent to a distant cloud data center for AI processing, the round-trip latency (even over a fast network) might be too high for safety or user experience. Therefore, we see a trend of pushing AI inference to the edge—closer to where data is generated and decisions are needed.
Benefits of ExpoTech’s Al Generated Data Centers’ AI Networking
-
Improved Scalability ExpoTech’s AI data center networking supports scalability by dynamically adapting to increased workloads and user demands. For colocation environments, this means better resource management and higher uptime.
-
Lower Latency By optimizing traffic routing and server communication, ExpoTech’s AI Networking will ensure faster data transfer speeds, which is critical for hosting environments requiring real-time processing.
-
Reduced Operational Costs Automating routine tasks and improving energy efficiency lowers operational costs. ExpoTech’s Al Generated Data Centers’ AI Networking will ensure resources are used optimally, avoiding wasteful power consumption and underutilized server capacities.
-
Enhanced User Experience ExpoTech’s Al Generated Data Centers’ AI Network will host services benefit from AI-driven performance improvements, providing end users with reliable and seamless experiences.
-
Proactive Problem-Solving Predictive analytics will help ExpoTech’s Al Generated Data Centers’ Network to identify and resolve potential issues before they impact operations, enhancing reliability and trust.
What are the attributes that makes the ExpoTech’s Al Generated Data Centers’ AI networking unique?
Networks are built to run AI workloads different than regular data center networks. While hyperscale, cloud resident data centers and HPC/AI clusters have a lot of similarities between them, the solution used in hyperscale data centers falls short for addressing the additional complexity imposed by HPC/AI workloads. Here are some examples of the attributes faced in an AI networking space:
-
Parallel computing AI workloads are a unified infrastructure of multiple machines running the same application and same computation task.
-
Size size of such task can reach thousands of compute engines (e.g., GPU, CPU, FPGA, Etc.).
-
Job types different tasks vary in their size, duration of the run, the size and number of data sets it needs to consider, type of answer it needs to generate, etc. this as well as the different language used to code the application and the type of hardware it runs on contributes to a growing variance of traffic patterns within a network built for running AI workloads
-
Latency & Jitter some AI workloads are resulting a response which is anticipated by a user. The job completion time is a key factor for user experience in such cases which makes AI latency an important factor. However, since such parallel workloads run over multiple machines, the latency is dictated by the slowest machine to respond. This means that while latency is important, jitter (or latency variation) is in fact as much a contributor to achieve the required job completion time
-
Lossless following on the previous point, a response arriving late is delaying the entire application. Whereas in a traditional data center, a message dropped will result in retransmission (which is often not even noticed), in an AI workload, a dropped message means that the entire computation is either wrong or stuck. It is for this reason that AI running networks requires lossless behaviour of the network. IP networks are loss by nature so for an IP network to behave as lossless, certain additions need to be applied. This will be discussed in. follow up to this paper.
-
Bandwidth large data sets are large. High bandwidth of traffic needs to run in and out of servers for the application to feed on. AI or other high performance computing functions is reaching interface speeds of 400Gbps per every compute engine in modern deployments.
ExpoTech’s Al Generated Data Centers’ Networking Challenges
-
High Complexity Managing this specialized infrastructure requires unique, high-skill sets, increasing operational overhead.
-
Power and Cooling AI racks are high-density, drawing 40-120kW, far exceeding traditional 8-10kW racks, requiring specialized liquid cooling and advanced power setups. But ExpoTech will generates its own electricity from Renewable Energy sources.
-
Balancing Cost and Performance While Ethernet is becoming cheaper, achieving high performance at massive scale remains expensive and complex but ExpoTech’s clients should be rest assured that ExpoTech will always take the first blunt of the hammer keeping the clients safe.
-
Latency & Jitter some AI workloads are resulting a response which is anticipated by a user. The job completion time is a key factor for user experience in such cases which makes AI latency an important factor. However, since such parallel workloads run over multiple machines, the latency is dictated by the slowest machine to respond. This means that while latency is important, jitter (or latency variation) is in fact as much a contributor to achieve the required job completion time
-
Lossless following on the previous point, a response arriving late is delaying the entire application. Whereas in a traditional data center, a message dropped will result in retransmission (which is often not even noticed), in an AI workload, a dropped message means that the entire computation is either wrong or stuck. It is for this reason that AI running networks requires lossless behaviour of the network. IP networks are loss by nature so for an IP network to behave as lossless, certain additions need to be applied. This will be discussed in. follow up to this paper.
-
Bandwidth large data sets are large. High bandwidth of traffic needs to run in and out of servers for the application to feed on. AI or other high performance computing functions is reaching interface speeds of 400Gbps per every compute engine in modern deployments.